Sous-titrage monolingue
La production de sous-titres monolingues destinés en particulier à les rendre accessibles au public sourd ou malentendant est devenue une obligation légale pour toutes les émissions télédiffusées depuis 2005, conduisant à une augmentation considérable du nombre d’heures sous-titrées. Cette étape est souvent la première marche vers la production de sous-titres en langue étrangère, qui permettront de démultiplier l’audience des émissions francophones. La production de sous-titres intervient souvent en bout de chaîne du processus de diffusion, et est principalement réalisée selon deux modalités très différentes : le sous-titrage en direct, pour les journaux d’information, les émissions de plateau ou les évènements retransmis en direct (par exemple, les émissions politiques ou les retransmissions de compétitions sportives) ; le sous-titrage en différé pour les émissions de jeux, les documentaires et les fictions. Dans le premier cas, des contraintes de temps réels sont critiques, et le sous-titreur doit s’adapter à la spontanéité des prises de parole et plus généralement aux aléas du direct ; dans le second cas, il faut potentiellement faire face à une plus grande variété des événements sonores à traiter et retranscrire : chansons, rires, bruits d’ambiance, interventions en langue étrangère, etc.

Dans cette étude, nous examinons la possibilité de concevoir des chaines de traitement automatisées des flux audios d’émissions télévisuelles en nous appuyant sur des méthodes modernes d’intelligence artificielle (IA), dont les avancées récentes ont permis d’améliorer considérablement la qualité d’applications telles que la transcription vocale et la traduction automatique. Deux questions sont principalement abordées : (a) est-il possible de parvenir à automatiser intégralement la production de sous-titres pour les émissions télévisuelles ? (b) La réponse est-elle la même pour tous les types et tous les genres d’émissions, ou bien certains sont-ils plus difficiles à traiter que d’autres ?
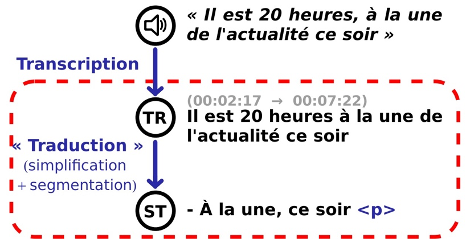
Pour essayer de répondre à ces questions, nous avons développé des algorithmes et des systèmes de sous-titrage entièrement automatisés. Partant d’une retranscription automatique de la bande son sous une forme textuelle, ces algorithmes utilisent des méthodes inspirées de la traduction automatique pour compresser les énoncés et calculer leur disposition à l’écran, afin de garantir qu’ils respecteront les standards les plus stricts d’affichage et de lisibilité. Dans un second temps, ces algorithmes ont été spécialisés et adaptés aux différents types d’émission, qui correspondent à des usages et à des publics variés : on peut vouloir regarder une émission pour s’informer, pour se divertir, ou encore pour apprendre de nouveaux savoir-faire, et les sous-titres ne remplissent pas exactement le même rôle dans ces trois situations.
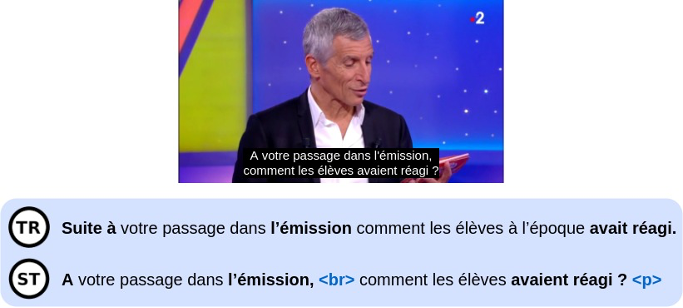
Des évaluations systématiques de ces algorithmes ont été mises en place ; d’un côté sur la base d’un jeu de test incluant une diversité d’émissions ; d’un autre côté sur la base d’une analyse par les spécialistes de france.tv access. Ces évaluations ont mis en évidence la faisabilité de systèmes de sous-titrage fonctionnant de bout en bout et adaptés aux types d’émissions, mais également les limites des systèmes actuels : si le niveau de qualité s’approche, pour certaines émissions de direct, du niveau d’exigence souhaité, la qualité moyenne reste très en deçà de la cible, et est inexploitable en particulier pour de nombreuses émissions sous-titrées en différées. Une raison de cette qualité médiocre provient des erreurs de retranscription, qui restent trop élevées ; une autre raison provient des systèmes de sous-titrage eux-mêmes, qui échouent à distinguer dans le flux audio les éléments de signification qui doivent être impérativement préservés.
Publications associées :