Outils et corpus LSF
Comme la constitution de logiciels de traitement automatiques dédiés aux langues des signes (LS) sont des travaux à long terme, nous avons lancé en parallèle trois études complémentaires qui ont porté sur la constitution d’outils autour des corpus de LS.
1. Logiciel de Traduction Assistée par Ordinateur français/LSF
La traduction automatique nécessite des données alignées et il en existe très peu en français/LSF. Un moyen d’en constituer plus est de développer des outils de type concordancier dans un environnement de traduction assistée par ordinateur (TAO), ce qui devrait permettre de collecter les alignements faits par les traducteurs professionnels. Ce type de logiciel n’existe pas encore pour les LS, donc nous avons lancé une étude (thèse de Marion Kaczmarek) sur ce sujet.
Afin de déterminer plus spécifiquement les étapes de la traduction français/LSF, deux études ont été menées avec des professionnels du métier : d’une part un brainstorming pour les amener à réfléchir et verbaliser leurs besoins et les problèmes rencontrés au quotidien dans leurs pratiques professionnelles, et d’autre part, des sessions où des binômes de traducteurs étaient filmés pendant qu’ils travaillaient sur la traduction de textes journalistiques. Cela a permis de dresser une liste des tâches inhérentes à la traduction en LS, mais également déterminer si elles étaient systématiques, et ordonnées.
A partir de ces observations, une liste de fonctionnalités a été élaborée pour un logiciel de TAO : traitement du texte source (par exemple repérage automatique des dates et des entités nommées), possibilité de modifier l’ordre des séquences, car cet ordre n’est pas identique en LS (qui place toujours le contexte avant) et dans les langues parlées, présence de modules d’aide (lexique, encyclopédie, carte géographique, etc.), mémoire de traduction et prompteur pour la réalisation finale.
Deux prototypes ont été réalisés. Une interface qui implémente les principes définis dans le cahier des charges (figure 1), ainsi qu’un concordancier bilingue (figure 2), basé sur un corpus parallèle de textes et de vidéos de traduction en LSF. Celui-ci est actuellement accessible en ligne sur une plateforme dédiée, et permet aux testeurs de faire des requêtes de mots ou ensemble de mots afin de pouvoir visualiser les extraits vidéo en LSF en contexte. Il reste à être intégré au logiciel de TAO.
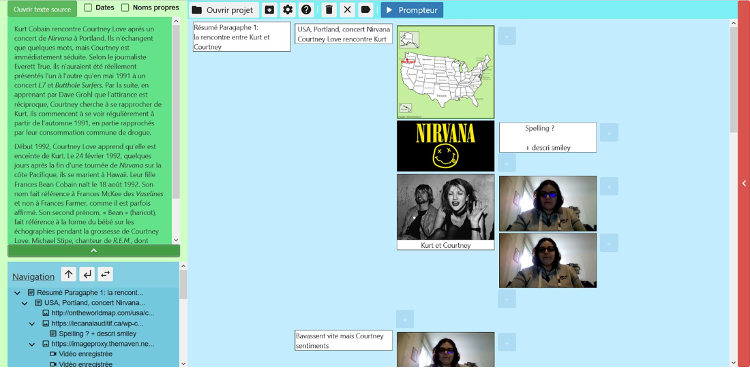
Figure 1 : Interface du prototype de logiciel de TAO texte vers LSF.
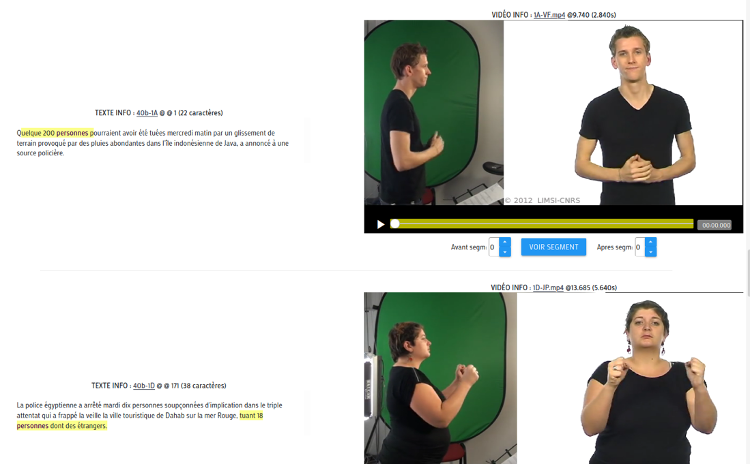
Figure 2 : Concordancier en ligne texte/LSF
Publications associées :
- Kaczmarek, M. Filhol (2019), Computer-assisted Sign Language translation: a study of translators’ practice to specify CAT software, 6th International Workshop on Sign Language Translation and Avatar Technology (SLTAT 2019), Hamburg, Germany.
- Kaczmarek, M. Filhol (2019), Assisting Sign Language Translation: what interface given the lack of written form and the spatial grammar?, 41st Translating and the Computer (TC 2019), Londres, United Kingdom, 83-92.
- Kaczmarek, M. Filhol (2020), Use cases for a Sign Language Concordancer, 9th Workshop on the Representation and Processing of Sign Languages (WRPSL@LREC 2020), 12th Int Conf on Language Resources and Evaluation (LREC2020), Marseille, France, 113-116.
- Kaczmarek, M. Filhol (2020), Alignments Database for a Sign Language Concordancer, 12th Int Conf on Language Resources and Evaluation (LREC2020), Marseille, France, 6069-6072.
- Kaczmarek, A. Larroque, M. Filhol. Logiciel de Traduction Assistée par Ordinateur des Langues des Signes. Colloque Handiversité 2021, Apr 2021, Orsay, France.
- Kaczmarek, A. Larroque (2021), Traduction Assistée par Ordinateur des Langues des Signes : élaboration d’un premier prototype, 28ème conférence sur le Traitement Automatique des Langues Naturelles, 2021, Lille, France. pp.108-122.
- Kaczmarek, M. Filhol. Computer-assisted sign language translation: a study of translators’ practice to specify CAT software – 2021 version. Machine Translation, Springer Verlag, 2021, 35 (3), pp.305-322.
2. Alignement automatique sous-titrage/LSF
La deuxième étude a consisté à explorer si de tels alignements peuvent être réalisés de manière automatique. Une étude (thèse de Hannah Bull) a été consacrée à l’alignement automatique entre les sous-titres et des segments de LSF avec une approche par apprentissage. Pour ce faire, nous avons développé un corpus parallèle de près de 30h, basé sur le site web de Media’Pi !, déjà partenaire du projet pour la constitution du corpus Rosetta (voir témoignage de Noémie Churlet). Une première version du système a été basée sur des éléments prosodiques tels que les pauses dans le mouvement, ou des postures spécifiques. Le travail actuel consiste à repérer dans la vidéo des segments qui correspondent à des « unités de sous-titrages », par une approche par apprentissage illustrée figure 3.
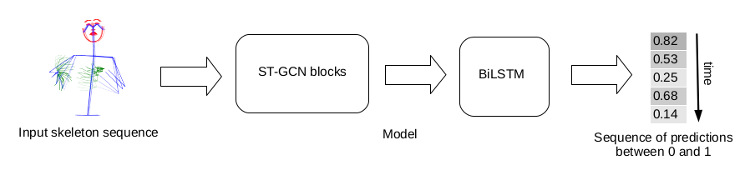
Figure 3 : Architecture du système de segmentation de vidéos de LSF en unités de type phrases.
Publications associées :
- Bull, A. Braffort, M. Gouiffès (2020), MEDIAPI-SKEL – A 2D-Skeleton Video Database of French Sign Language With Aligned French Subtitles, 12th Int Conf on Language Resources and Evaluation (LREC2020), Marseille, France, 6063-6068.
- Bull, A. Braffort, M. Gouiffès (2020), Corpus Mediapi-skel sur Ortolang : https://www.ortolang.fr/market/corpora/mediapi-skel (56 téléchargements)
- Bull, A. Braffort, M. Gouiffès (2020), Automatic Segmentation of Sign Language into Subtitle-Units, Sign Language Recognition, Translation & Production workshop (SLRTP20), 16th European conference on computer vision (ECCV’20) – Best paper award.
3. Anonymisation des animations
Enfin, une troisième étude (thèse de Félix Bigand) a porté sur la nature des données collectées dans le projet. Comme la génération des animations est réalisée à partir de données captées à l’aide d’un système de capture de mouvement très précis, il est tout à fait possible de reconnaître la personne qui a été « mocapée », même si les traits de l’avatar sont très différents de ceux de la personne enregistrée, ce qui peut être problématique dans certains contextes. L’objectif est d’identifier quels sont les paramètres du mouvement qui définissent le style individuel des signeurs, de manière à pouvoir jouer sur ces paramètres pour rendre la LSF enregistrée anonyme, tout en la gardant parfaitement compréhensible.
Après des études sur la structure complexe des mouvements en LSF, le travail s’est centré sur la problématique de l’identification des locuteurs par leur mouvement, avec 3 autres contributions :
- Une étude de perception visuelle qui a permis de démontrer que les sujets étaient capables de reconnaître la personne qui s’exprimait à partir d’un simple extrait court sous forme de point lumineux en mouvement (figure 4).
- Un modèle par apprentissage basé sur les données statistiques issues du corpus MOCAP1 pour chaque signeur (figure 5). Les paramètres de la signature cinématique de l’identité des signeurs a pu être définie grâce à ce modèle.
- Un algorithme de synthèse qui permet de modifier les paramètres définissant la signature cinématique des signeurs, qui peut être appliqué à l’anonymisation (figure 6).

Figure 4 : Exemple d’affichage par points lumineux utilisé dans l’expérimentation.
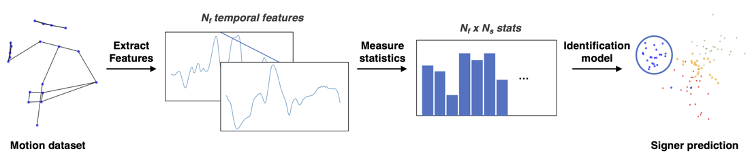
Figure 5 : Schéma des étapes utilisées dans le modèle d’apprentissage pour l’identification.
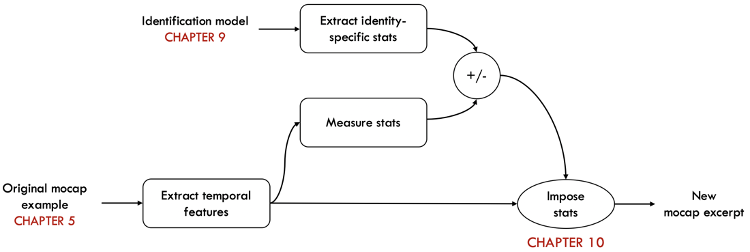
Figure 6 : Schéma des étapes de l’algorithme de synthèse pour le contrôle cinématique de l’identité.
Publications associées :
- Bigand, A. Braffort, E. Prigent, B. Berret (2019), Signing Avatar Motion: Combining Naturality and Anonymity, 6th International Workshop on Sign Language Translation and Avatar Technology (SLTAT 2019), Hambourg, Germany.
- Bigand, E. Prigent, A. Braffort (2019), Animating virtual signers: the issue of gestural anonymization, 19th International Conference on Intelligent Virtual Agents (IVA 2019), Paris, France.
- Bigand, E. Prigent, A. Braffort (2019), Retrieving Human Traits from Gesture in Sign Language: The Example of Gestural Identity, 6th International Symposium on Movement and Computing (MOCO 2019), Tempe, United States.
- Bigand, E. Prigent, A. Braffort, B. Berret (2019), Animer un signeur virtuel par mocap : le problème de l’identité gestuelle, 5è Journée de la Fédération Demeny-Vaucanson (FéDeV 2019), Palaiseau, France.
- Bigand, E. Prigent, A. Braffort (2020), Person Identification Based On Sign Language Motion: Insights From Human Perception And Computational Modeling, 7th International Conference on Movement and Computing (MOCO’20).
- Bigand, E. Prigent, B. Berret, A. Braffort. How Fast Is Sign Language? A Reevaluation of the Kinematic Bandwidth Using Motion Capture. 29th European Signal Processing Conference (EUSIPCO 2021), 2021.
- Bigand, E. Prigent, B. Berret, A. Braffort. Machine Learning of Motion Statistics Reveals the Kinematic Signature of the Identity of a Person in Sign Language. Frontiers in Bioengineering and Biotechnology, Frontiers, 2021, 9.
- Bigand, E. Prigent, B. Berret, A. Braffort. Decomposing spontaneous sign language into elementary movements: A principal component analysis-based approach. PLoS ONE, Public Library of Science, 2021, 16 (10).