Traduction texte vers LSF
L’une des spécificités de la traduction depuis un texte vers une langue des signes (LS) est la différence de canal. En effet, les LS n’ont pas de forme écrite et il faut donc produire du contenu sous forme visuo-gestuelle. La solution consiste à passer par une représentation intermédiaire, et procéder en deux étapes :
- traduire le texte en français sous cette représentation intermédiaire
- utiliser cette représentation comme entrée pour un système d’animation qui permet d’afficher un signeur virtuel animé
Les choix retenus pour le projet ont été les suivants :
- L’utilisation d’AZee, développé au LISN, comme représentation intermédiaire, représentation qui a déjà fait ses preuves pour la génération et qui tire pleinement parti des correspondances entre message et mouvement contenues dans les données. En étant basée sur la langue d’arrivée, la LSF, et non la langue de départ, le français, cette représentation est aussi plus proche d’une formulation naturelle en langue cible, ce qui facilite la compréhension du message et la génération.
- Une traduction du texte vers AZee par analogie, en reconstituant de nouvelles phrases à partir d’exemples disponibles, qui nous permet de pointer précisément dans le format cible (la représentation intermédiaire) ce qui doit être extrait et combiné : l’enjeu devient alors l’identification dans les exemples disponibles des constituants correspondants à la phrase que l’on souhaite traduire, la traduction des nouveaux constituants et la combinaison des résultats.
- La création d’un corpus parallèle français/LSF enregistré à l’aide d’un système de capture de mouvement par Mocaplab et qui doit permettre de générer une animation à partir de segments d’animations présents dans le corpus.
ROSETTA-LSF : corpus bilingue français/LSF
Pour traduire du texte vers AZee, il nous faut une banque d’alignements entre chaque segment de texte et des expressions AZee, chacune représentant par définition une traduction possible pour le segment textuel. Puisque les expressions AZee sont ensuite utilisées pour animer l’avatar à partir de données mocap, il nous faut également un alignement entre les données enregistrées sur de vraies productions de référence et les expressions AZee qui les représentent. Cela nous a amené à créer le corpus de mocap ROSETTA-LSF et à réaliser des alignements français/AZee/LSF afin de pouvoir travailler sur les deux fronts, de part et d’autre de ce pivot qu’est AZee.
Afin de pouvoir constituer une banque de données mocap réutilisables et combinables, la 1ère étape a consisté à définir un schéma d’annotation du corpus qui permet d’ajouter des indications nécessaires et suffisantes sur les aspects linguistiques pour pouvoir à la fois sélectionner les segments utiles et les adapter dans un nouveau contexte pour la génération.
Alignements avec français/AZee et AZee/LSF
Le travail suivant a consisté à réaliser les alignements texte/AZee/LSF. Le système AZee préexistait au projet ROSETTA. Le projet nous a permis de l’ajuster et de le stabiliser, par un travail d’alignement AZee/LSF, dans un premier temps sur un corpus préexistant (corpus 40 brèves), puis sur le corpus ROSETTA-LSF quand il a été disponible. Cet alignement a consisté à produire des expressions AZee (AZeefication) pour chaque vidéo de LSF. Il s’agit de repérer les règles de production AZee et de les imbriquer entre elles, par l’observation des formes (impliquant des articulateurs manuels et/ou non-manuels) produites par le signeur et l’interprétation du sens qui leur est associé. Ce travail, réalisé à la main par des experts en linguistique de la LSF, a nécessité une vérification constante à tous les niveaux de l’expression : arbres et sous-arbres AZee, règles de production. Une banque de données de 180 expressions AZee de discours a ainsi été constituée sur le corpus ROSETTA-LSF.
Ensuite, nous avons réalisé des alignements AZee/texte par la recherche de correspondances entre tout ou partie d’une expression AZee et tout ou partie du texte. Chaque expression AZee correspondant à un texte, de premiers alignements AZee-texte sont ainsi formés. Étant donné que chaque expression AZee est composée de sous-expressions et que chaque titre d’actualité peut être décomposé en plusieurs segments, d’autres alignements viennent compléter la liste par affinage successif. Dans le cas des segments impliqués dans les phrases à traduire retenues, un dernier alignement manuel des expressions AZee avec les timecodes des enregistrements de mocap a été effectué pour la manipulation et combinaison effectives des blocs de mouvement.
Modules de traduction texte/AZee et génération AZee/LSF
Finalement, nous avons réalisé les modules de traitement automatique nous permettant de traduire une phrase en français écrit en LSF via l’animation de signeur virtuel.
Pour une phrase à traduire (dans notre cas un titre de journal), nous cherchons à associer un ensemble de traductions possibles en description AZee, en procédant par recherche d’analogies dans notre corpus d’alignements. L’approche retenue est de procéder en tentatives successives sur trois niveaux différents : traduction 1) par match exact, 2) par anti-match, 3) par partition. Chaque niveau produit des traductions de qualité inférieure au niveau précédent, mais ce niveau n’est tenté que si le précédent n’a pas abouti. Cette première étape nous permet d’obtenir une description de la phrase en AZee, qui est ensuite utilisée pour produire le message en LSF.
Au niveau de la génération de l’animation, la structure récursive de AZee implique la formation de blocs de mouvement, chaque bloc étant éventuellement composé de sous-blocs définis par les sous-expressions AZee. Le principe général de la méthodologie de combinaison, appelée “multi-canaux”, repose sur le fait de gérer le mouvement de manière synchrone sur plusieurs canaux d’animation. Chaque canal correspondant à un ensemble d’os représentant des effecteurs tels que les mouvements du bras droit, du bras gauche, du tronc, de la tête et du reste du corps. Ainsi, la génération de nouvelles animations peut être constituée de segments incluant tous les éléments corporels ou de segments ne portant que sur un ou plusieurs éléments (par exemple uniquement la tête).
Le schéma suivant illustre l’approche retenue.
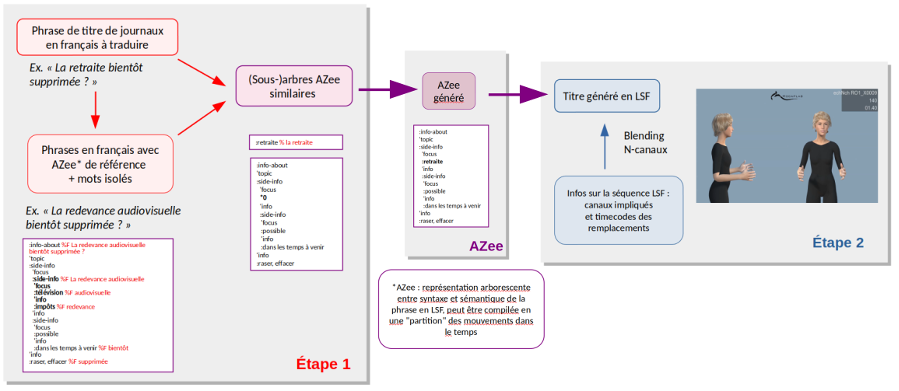
Par exemple, pour générer la traduction en LSF de la phrase :
Alsace : de grands chefs ont vendu leur vaisselle pour les plus modestes dans la banlieue de Gerstheim
Le système a utilisé les trois phrases suivantes présentes dans le corpus ROSETTA-LSF :
- Samedi 30 et dimanche 31 mars, de grands chefs ont vendu leur vaisselle en Alsace, à Gerstheim
- Moins de TVA pour les plus modestes : « Il ne faut pas traiter ça par le mépris », lance Xavier Bertrand au gouvernement
- Le superéthanol n’est proposé que dans 1 000 stations-service en France, comme ici dans la banlieue de Bordeaux
Et a généré une description en AZee utilisée elle-même pour générer une traduction en LSF via l’animation du signeur virtuel.
Résultats et perspectives
L’ensemble des algorithmes a été implémenté et testé sur des exemples représentatifs afin de disposer d’une preuve de concept de l’approche retenue. Il s’agit de 7 titres non présents dans le corpus, qui ont été sélectionnés pour leur représentativité des phénomènes à prendre en compte dans le cadre de ce projet et sont présentés dans le démonstrateur final.
Les recherches sur le traitement automatique des langues des signes est très récent : au début du projet, il n’existait pas de système de traduction automatique français/LSF, et s’il existait des systèmes de générations d’animations en LSF, ils étaient généralement basés sur la concaténation d’animations “monocanal”, cela limitant la qualité linguistique des productions ainsi que leur réalisme physiologique.
Côté traduction, nous avons expérimenté une approche de traduction par analogie, avec une représentation intermédiaire, AZee, qui permet une bien meilleure précision sur les aspects linguistiques. Côté génération d’animations, nous avons expérimenté une approche “multicanaux” qui permet de bénéficier de cette meilleure précision linguistique et de produire des animations plus réalistes. Les évaluations utilisateurs ont attesté la supériorité de cette méthode par rapport aux préexistantes, en montrant de meilleurs scores sur les aspects effort cognitif, compréhension et satisfaction.
Ainsi, s’il reste encore beaucoup de travail de recherche et développement à mener avant d’aboutir à un produit commercialisable, nous avons pu réaliser une preuve de concept opérationnelle qui nous a permis de valider nos choix et nous offre des perspectives de progression pour les prochaines années.