Text to LSF Translation
The project choices were:
- The use of AZee, developed at LISN, as an intermediate representation, which has already proved its worth for SL generation and which takes full advantage of the correspondence between message and movement contained in the data. Based on the language of arrival, LSF, and not the source language, French, this representation is also closer to a natural target language formulation, which facilitates understanding of the message and generation.
- A translation from text to AZee by analogy, reconstructing new sentences from available examples, which allows us to point precisely in the target format (the intermediate representation) what needs to be extracted and combined: the issue then becomes the identification in the available examples of the constituents corresponding to the sentence to be translated, the translation of the new constituents and the combination of the results.
- The creation of a parallel French/French Sign Language corpus recorded using a motion capture (mocap) system by Mocaplab which makes it possible to generate an animation from segments of animations present in the corpus.
One of the specifics of translation from text to sign language (SL) is the channel difference. SL do not have a written form and therefore content must be produced in visual-gestural form. The solution is to go through an intermediate representation, and proceed in two steps:
- translate the French text into this intermediate representation
- use this representation as input for an animation system that allows an animated virtual signer to be displayed
ROSETTA-LSF: French/LSF bilingual corpus
To translate text to AZee, we need a bank of alignments between each text segment and AZee expressions, each of which is by definition a possible translation for the text segment. Since AZee expressions are then used to animate the avatar from mocap data, we also need an alignment between the data recorded on real reference productions, and the AZee expressions that represent them. This led to the creation of the ROSETTA-LSF mocap corpus and the realization of French/AZee/LSF alignments so that we could work on both sides of this pivot that is AZee.
In order to build a reusable and combinable mocap database, the first step was to define a corpus annotation scheme that allows for the addition of necessary and sufficient language aspects to be able both to select the useful segments and to adapt them in a new context for generation.
French/AZee and Azee/LSF alignments
The next work was to perform text/AZee/LSF alignments. The AZee system preexisted the ROSETTA project. The project allowed us to adjust and stabilize it, by an AZee/LSF alignment work, first on a pre-existing corpus (40 brèves corpus), then on the ROSETTA-LSF corpus when it became available. This alignment consisted of producing Azee expressions (AZeefication) for each LSF video. The aim is to identify and interweave the AZee production rules by observing the forms (involving manual and/or non-manual articulators) produced by the signer and interpreting the meaning associated with them. This work, carried out by hand by LSF linguistic experts, required constant verification at all levels of expression: AZee trees and subtrees, production rules. A database of 180 expressions of AZee expressions from speech was thus created with the ROSETTA-LSF corpus.
We then performed AZee/text alignments by finding matches between all or part of an AZee expression and all or part of the text. Each AZee expression corresponding to a text, first AZee-text alignments are thus formed. Since each AZee expression is composed of sub-expressions and each news headline can be broken down into several segments, other alignments complete the list by successive refinements. In the case of the segments involved in the selected sentences to be translated, a final manual alignment of the Azee expressions with the timecodes of the mocap recordings was carried out for the effective manipulation and combination of the movement blocks.
Text/AZee translation modules and AZee/LSF generation
Finally, we created the automatic processing modules allowing us to translate a sentence in written French to French Sign Language via the virtual signer animation.
For a sentence to be translated (in our case a news headline), we seek to associate a set of possible translations in AZee description, by searching for analogies in our corpus of alignments. The approach chosen is to proceed in successive attempts on three different levels: translation 1) by exact match, 2) by anti-match, 3) by partition. Each level produces lower quality translations than the previous level, but this level is only attempted if the previous level has not been successful. This first step allows us to obtain a description of the sentence in AZee, which is then used to produce the message in French Sign Language.
At the level of animation generation, the recursive structure of AZee involves the formation of movement blocks, each block possibly being composed of sub-blocks defined by the AZee sub-expressions. The general principle of the combination methodology, called “multi-channel”, is based on the fact that the movement is managed synchronously on several animation channels. Each channel corresponds to a set of bones representing effectors such as the movements of the right arm, the left arm, the trunk, the head and the rest of the body. Thus, the generation of new animations may consist of segments including all the body elements or segments relating only to one or more elements (for example only the head).
The following diagram illustrates the approach taken.
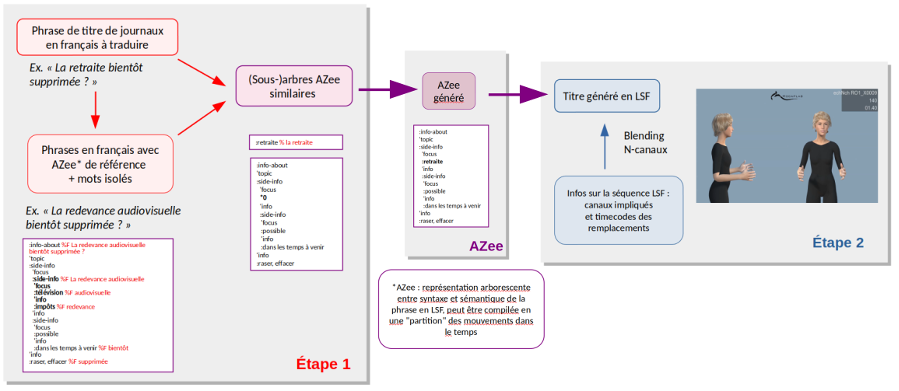
For example, to generate the French Sign Language translation of the sentence:
Alsace : de grands chefs ont vendu leur vaisselle pour les plus modestes dans la banlieue de Gerstheim
The system used the following three sentences in the ROSETTA-LSF corpus:
- Samedi 30 et dimanche 31 mars, de grands chefs ont vendu leur vaisselle en Alsace, à Gerstheim
- Moins de TVA pour les plus modestes : “Il ne faut pas traiter ça par le mépris”, lance Xavier Bertrand au gouvernement
- Le superéthanol n’est proposé que dans 1 000 stations-service en France, comme ici dans la banlieue de Bordeaux
And generated a description in Azee, itself used to generate an LSF translation via the virtual signer animation.
Results and prospects
The set of algorithms was implemented and tested on representative examples in order to have a proof of concept of the chosen approach. These are 7 titles not present in the corpus, which have been selected for their representativeness of the phenomena to be taken into account in this project, and are presented in the final demonstrator.
Research on automatic processing of sign languages is very recent: at the beginning of the project, there was no French/French Sign Language machine translation system, and although there were systems for generating animations in French Sign Language, they were generally based on the concatenation of “single channel” animations, which limits the linguistic quality of the productions as well as their physiological realism.
On the translation side, we have experimented with an translation by analogy approach, with an intermediate representation, AZee, which allows much better accuracy on linguistic aspects. In terms of generating animations, we have experimented with a “multi-channel” approach that allows us to benefit from this better linguistic precision and produce more realistic animations. User evaluations demonstrated the superiority of this method over pre-existing ones, showing better scores on aspects of cognitive effort, understanding and satisfaction.
Thus, while there is still a lot of research and development work to be done before we reach a marketable product, we have been able to produce a proof of concept that has enabled us to validate our choices and offers us prospects for progress in the coming years.